
{kind=link}
A comparison of the single, conditional and person-specific standard error of measurement
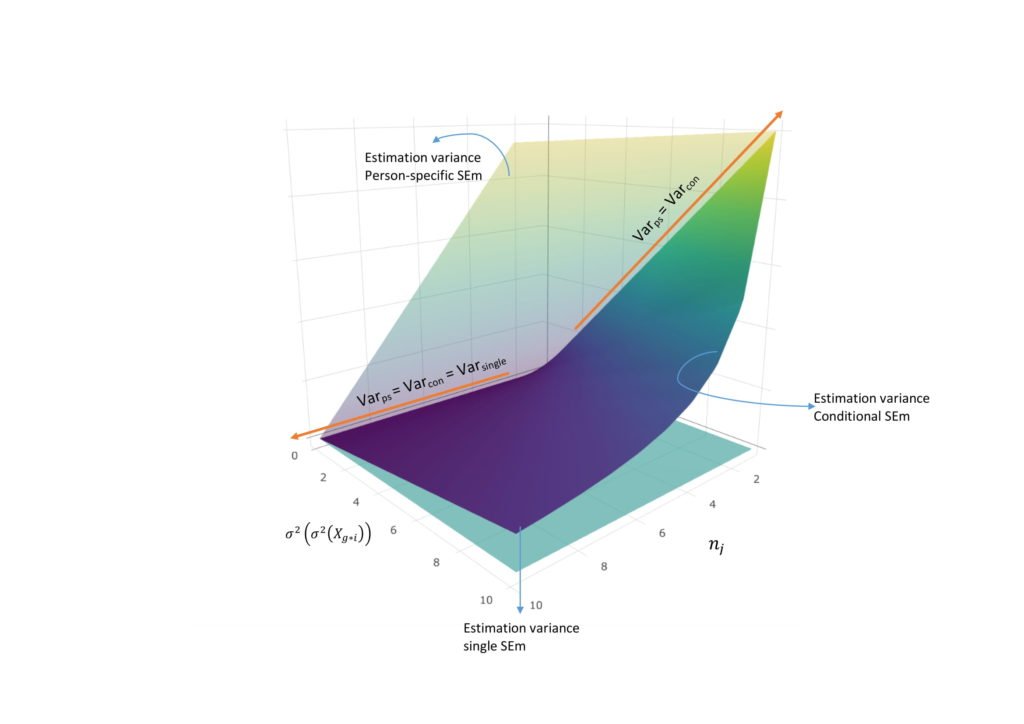
Tests based on the Classical Test Theory often use the standard error of measurement (SEm) as an expression of (un)certainty in test results. Although by convention a single SEm is calculated for all examinees, it is also possible to (1) estimate a person-specific SEm for every examinee separately or (2) a conditional SEm for groups of comparable examinees. The choice for either of these SEms depends on their underlying assumptions and the trade-off between their unbiasedness and estimation variance. These underlying assumptions are discussed in the present article, together with a mathematical expression of the bias and estimation variance of each of the SEms. Using a simulation study, we furthermore show how characteristics of the test situation (i.e., test length, number of items, number of parallel test parts, overall reliability, relationship between ‘true’ score and true (un)certainty in test results and rounding/truncation) influence the SEm-estimates and impact our choice for one of the SEms. Following the results of the simulation study, especially rounding appears to hugely affect the person-specific and – to a lesser extent – the conditional SEm. Therefore, when a test is small and an examinee is only tested once or a few times, it is safer to opt for a single SEm. Overall, a conditional SEm based on coarse grouping appears to be a suitable compromise between a stable, but strict estimate (like the single SEm) and a lenient, but highly variable estimate (like the person-specific SEm). More practical recommendations can be found at the end of the article.
Lek, K.M. & Van de Schoot, R. (2018). A comparison of the single, conditional and person-specific standard error of measurement: what do they measure and when to use them? Frontiers in Applied Mathematics and Statistics. DOI: 10.3389/fams.2018.00040

All R-scripts to reproduce the results can be found on the Open Science Framework: https://osf.io/6km3z/
Kimberley works together with Rens on how educational and psychological tests can be improved with new and existing statistical tools. One project focusses, for instance, on how (un)certainty in the test results of individual examinees can be estimated and expressed, to ...