
Expert Data (Dis)agreement
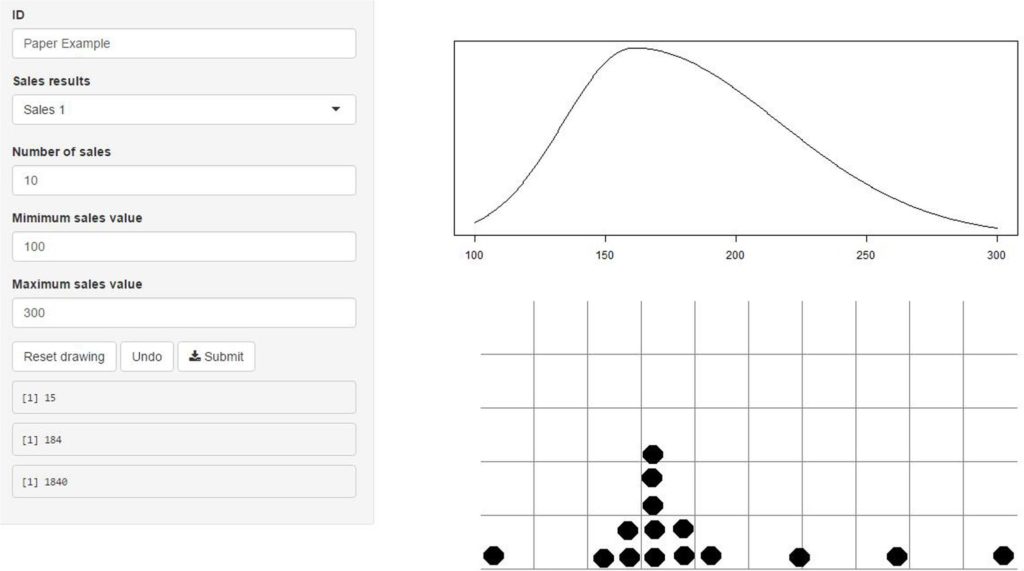
Elicitation is the process of extracting knowledge about the parameters in the statistical model. This information can then be used to provide input for the prior distribution needed for Bayesian analysis. Several methods of prior elicitation are used in practice including the use of experts.
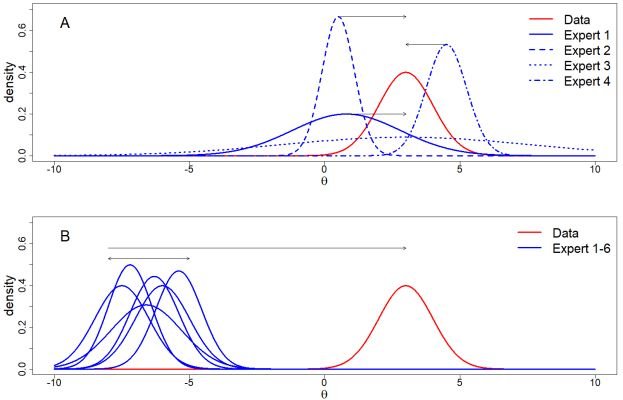
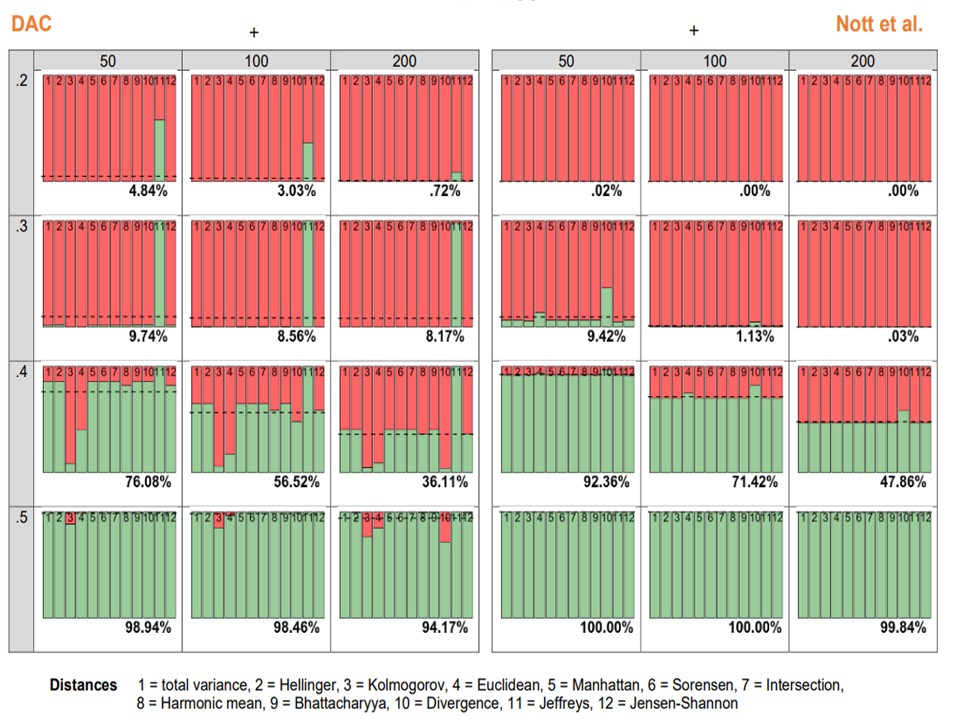
Most studies, however, rely on results of previous publications as input for the prior distributions. In the current project I propose to use experts’ knowledge to provide the necessary background knowledge. When expert knowledge and the estimates solely based on the data agree, the Bayesian results lead to similar estimates as compared to ML-estimation, but with an increase in statistical power and smaller confidence/credibility intervals. However, when expert knowledge and collected data disagree the posterior estimates are influenced by the expert knowledge. This is because the Bayesian results are a compromise between the two sources of information. Such a disagreement is what is called a prior-data conflict, but I propose to use the term expert-data conflict when it concerns experts opinions. Whereas other fields increasingly appreciate this expert-data conflict, in the social sciences use of expert knowledge in this way is hardly ever used. The main reason might be that the estimates based on the data are trusted more than the subjective opinions of experts. But these arguments only hold if the data is truly a random sample from the population, which is almost never the case with limited data. In these situations, the data may be quite unreliable and I argue balancing the two sub-optimal sources of information via Bayesian statistics leads to more reliable conclusions than relying on imperfect data alone. Also, by quantifying the expert-data conflict a new type of research question can be answered: which expert, or group of experts disagree most with the data? Answering such question opens a new area of research which can be especially useful to identify biased experts or for policy makers who can then focus their campaign on specific misconceptions between groups of experts.
Ongoing
In my VIDI*-project we work on several projects related to small data. [more information will follow soon]
*The VIDI is part of the innovational research incentives scheme of The Netherlands Organization for Scientific Research. The VIDI is the second (out of three) grants to develop their own research group.
In her current projects, Milica is focusing on optimal methods for data synthesis from non-exchangeable studies, on the consequences of specifying inaccurate priors in mediation models, and on issues that arise in applications of Bayesian mediation analysis with informative prior distributions in small samples.
Kimberley works together with Rens on how educational and psychological tests can be improved with new and existing statistical tools. One project focusses, for instance, on how (un)certainty in the test results of individual examinees can be estimated and expressed, to ...
Ducos PhD project with Rens focusses on providing a solution to small data problems in latent growth curve models. With few data points, it can be impossible to estimate the model of interest. Yet asking a different (simplified) question the data can answer may not be desirable.
In her PhD project, Mariëlle focuses on including prior knowledge in statistical analyses (informative Bayesian research) and confronting prior knowledge with new data.



After working with Rens on various research projects related to Bayesian Estimation and latent growth modeling I developed an interest in researching both of these further.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}